
阅读时间:7分钟
发布日期:2023年12月21日
2023年,随着ChatGPT的推出,生成式人工智能的关注度爆炸式增长。从初创公司到企业,各类公司都在尝试制定自己的生成式人工智能(GenAI)战略。
“我们如何将生成式人工智能融入我们的产品?”
“我们应该遵循哪些参考架构?”
“哪些模型最适合我们的用例?”
“我们应该使用什么技术栈?”
“如何测试我们的LLM应用?”
这些都是各家公司正在思考的问题。在如此不确定的时期,每个人都希望了解其他人正在做些什么。虽然目前已经有一些尝试揭示这些问题,但凭借LangChain在生态系统中的独特地位,我们相信可以更清晰地展示团队如何使用LLMs进行构建。
为此,我们依靠LangSmith中的匿名元数据。LangSmith是我们的云平台,旨在简化从原型到生产的过渡。它提供追踪、回归测试与评估等功能。目前平台仍处于私测阶段,但我们每天都在邀请用户注册。如果您对企业访问或支持感兴趣,请随时联系我们。
通过这些数据,我们可以回答以下问题:人们在构建什么?他们是如何构建的?以及他们如何测试这些应用?以下统计数据的时间范围为2023年7月2日至2023年12月11日。
人们在构建什么?
我们来看看人们普遍在构建的一些内容。

虽然LangSmith与LangChain无缝集成,但在LangChain生态系统之外也可轻松使用。我们发现LangSmith的使用量中约有15%来自未使用LangChain的用户。我们致力于使上述所有组件的入门体验无论是否使用LangChain都同样流畅。
检索成为主流
检索已成为将数据与LLM结合的主要方式。LangChain提供60多个向量存储的集成(这是索引非结构化数据的最常用方式)。LangChain还提供许多高级检索策略。数据显示,42%的复杂查询涉及检索,这既反映了检索的重要性,也体现了LangChain在简化检索方面的优势。
智能体功能的使用
大约17%的复杂查询属于智能体任务。智能体功能允许LLM决定采取哪些步骤,从而使系统能够更好地处理复杂查询或边缘情况。然而,由于智能体的可靠性和性能尚未完全优化,这一比例仍然较低。
LCEL的使用情况
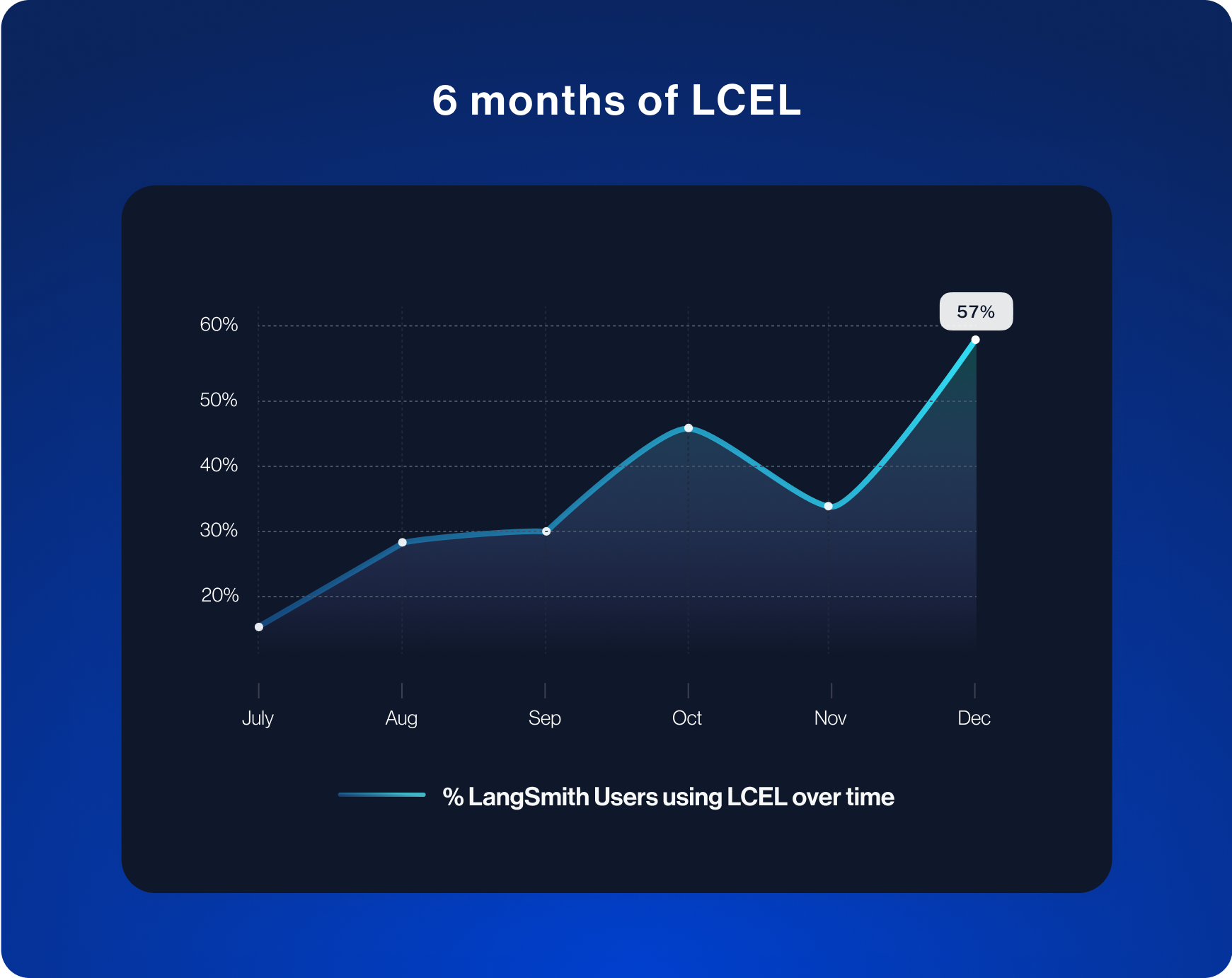
过去几个月LangChain的一项重大更新是引入了LangChain表达式语言(LCEL)。它是一种轻松组合组件的方式,非常适合创建复杂的自定义链。在生成式人工智能发展的初期,大家都在尝试摸索如何最佳利用LLM。这需要大量的实验和定制,而LCEL简化了这一过程。随着更多功能的加入和文档的改进,我们观察到其使用量在过去几个月迅速增加。
最常用的LLM提供商
LLM是这一切的核心技术。那么,哪些LLM提供商最受欢迎?

正如预期,OpenAI位居榜首,AzureOpenAI紧随其后。2023年,OpenAI已成为领先的LLM提供商,而Azure凭借更多企业级保证很好地接续了这一势头。
其他提供专有模型的托管服务包括Anthropic(第3名)、Vertex AI(第4名)和Amazon Bedrock(第8名)。
在开源模型方面,Hugging Face(第4名)、Fireworks AI(第6名)和Ollama(第7名)成为用户与这些模型交互的主要方式。
排名依据:使用特定提供商的用户数量
最常用的开源模型提供商
最近,开源模型越来越受关注,许多提供商争相以更低成本托管这些模型。那么开发者是如何使用这些开源模型的?

我们发现,大多数用户倾向于本地运行这些模型,主要使用的选项包括Hugging Face、LlamaCpp、Ollama和GPT4All。
在提供API访问开源模型的提供商中,Fireworks AI领先,其次是Replicate、Together和Anyscale。
排名依据:使用特定提供商的用户数量
最常用的向量存储
正如前文提到的,检索是LLM应用的重要部分。向量存储正在成为检索相关上下文的主要方式。LangChain拥有60多个向量存储集成,那么人们最常用的是哪些?

数据显示,本地向量存储最受欢迎,Chroma、FAISS、Qdrant和DocArray均进入前五。由于排名依据是使用特定向量存储的用户数量,因此本地免费向量存储的高使用率也在情理之中。
在托管服务中,Pinecone领先,是前五名中唯一的托管向量存储。Weaviate紧随其后,这表明向量原生数据库的使用率高于新增向量功能的传统数据库。
新增向量功能的数据库中,Postgres(PGVector)、Supabase、Neo4j、Redis、Azure Search和Astra DB位居前列。
最常用的嵌入向量生成工具
为了使用向量存储,必须为文本片段计算嵌入向量。那么开发者是如何做到这一点的呢?

与LLM类似,OpenAI依然占据主导地位,但在其后我们看到了更多的多样性。开源提供商的使用率更高,其中Hugging Face位居第二,GPT4All和Ollama也跻身前八。
在托管服务方面,Vertex AI 的使用率实际上超过了 AzureOpenAI,而 Cohere 和 Amazon Bedrock 也紧随其后。
高级检索策略
仅仅通过余弦相似性进行检索在很多场景中已不够用。我们发现许多人依赖高级检索策略,而LangChain实现并记录了许多此类策略。

即便如此,最常用的检索策略并非内置策略,而是自定义策略。这说明:
在LangChain中实现自定义检索策略非常容易。
为了实现最佳性能,自定义逻辑是必要的。
其次,我们看到了一些熟悉的名字:
自查询(Self Query):从用户问题中提取元数据过滤器。
混合搜索(Hybrid Search):主要通过特定提供商集成(如Supabase和Pinecone)实现。
上下文压缩(Contextual Compression):对基础检索结果进行后处理。
多查询(Multi Query):将单个查询转换为多个查询,然后检索所有结果。
时间加权向量存储(TimeWeighted VectorStore):对最新文档赋予更高权重。
测试与评估 How are people testing?
测试和评估是开发LLM应用时的主要难点之一,而LangSmith正成为解决这一问题的最佳工具之一。

数据显示,大多数用户能够制定某种指标来评估其LLM应用——83%的测试运行包含某种形式的反馈。具有反馈的运行平均包括2.3种不同类型的反馈,这表明开发者难以找到单一的可靠指标,而是使用多种指标进行评估。
在记录的反馈中,大多数使用LLM来评估输出。尽管这一方法引发了一些担忧,但实际上它已成为主流测试方式。另一个值得注意的数据是,近40%的评估器为自定义评估器。这与评估通常需要针对特定应用进行高度定制的事实相一致,没有通用的评估器可以完全满足需求。
测试重点 What are people testing?
我们发现,大多数人仍主要关注其应用的正确性(而非毒性、提示泄露或其他防护措施)。从精确匹配作为评估技术的低使用率也可以看出,判断正确性往往非常复杂(不能仅简单比较输出是否完全一致)。

结论
作为LLM应用开发的第一个完整年度结束,我们听到许多团队表示,他们希望缩短从原型到生产的差距。希望这些使用统计数据可以帮助揭示人们在构建什么、如何构建以及如何测试这些内容。
LangSmith正成为团队将应用从原型推向生产的主要方式,无论是否使用LangChain。如果您对企业访问或支持感兴趣,请联系我们或注册。